
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 |
- 해킹
- 알고리즘
- 백준
- 리눅스
- C언어
- 보안
- 리액트
- 웹해킹
- 자바스크립트
- 넘파이
- CodeEngn
- MySQL
- abex crackme
- 인공지능
- 어셈블리어
- 웹
- webhacking.kr
- sql injection
- 머신러닝
- writeup
- 리버싱 워게임
- 리버싱 문제
- 백준 알고리즘
- 회귀 수식
- 리버싱
- webhacking
- html
- 컴퓨터 구조
- php
- 워게임
- Today
- Total
인공지능 개발일지
[데이터 분석] Pandas 사용법 요약 정리와 활용 팁 (함수의 조합 활용하기) 본문
안녕하세요! 이번 시간에는 판다스에 대해 알아봅시다.
판다 스는 제가 좋아하는 언어고 Python의 장점인 문법의 유연함을 100%로 활용한 라이브러리 같습니다. 여담으로 Pandas는 MySQL을 좀 더 시각적으로 더 활용해서 다룰 수 있는 언어 같다고 느꼈습니다. 그리고 테이블 형태의 데이터를 다루는데 최적화된 언어 같습니다. 한 번 알아봅시다.
지난 시간에는 판다스와 같이 잘 쓰이는 선형대수 라이브러리 Numpy에 대해 알아봤는데요.
혹시 이에 대한 선행학습이 되어 있지 않다면 이 게시글과 함께 실습해 보는 것도 추천드립니다.
물론 아래 정리된 내용 말고 현재도 계속 라이브러리가 계속 업데이트되어서 종류가 매우 많지만 우선 기본적인 것 위주로 정리했습니다. 제가 4달 동안 이것만 붙잡고 하다 보니 느낀 점이 익숙해지는 게 최고다. 손에 익으면 편하다.
그렇지만 제가 이 포스팅을 통해 전달드리고 싶은 것은 제가 Pandas를 이해하게 된 핵심 포인트를 위주로 정리해봤습니다.
목차
1. Pandas의 기본 데이터 타입 Series와 DataFrame
2. Series와 DataFrame 생성 방법
3. iloc와 loc를 활용한 데이터 조회 및 입력
4. 칼럼 추가/삭제
5. 유용한 메서드 모음
6. 결측치 처리
1. Pandas의 기본 데이터타입 Series와 DataFrame
판다스의 데이터 타입에는 Series와 DataFrame이 있습니다.
둘 다 테이블 형태의 데이터를 나타낸다는 점은 동일하지만 다른 것은 칼럼의 개수입니다. Series는 칼럼이 하나이고 DataFrame은 칼럼이 2개 이상인 자료구조를 나타냅니다.
시리즈와 데이터 프레임에 대해 알아보기 전에 판다스의 시리즈에 대해 먼저 알아봅시다. 인덱스는 말 그대로 아래와 같은 데이터 프레임이 있을 때 가장 왼쪽의 0,1과 같이 행을 식별하는 숫자를 인덱스라고 합니다. 그래서 아래와 같은 데이터 프레임에서 칼럼은 a, b, c 세 개에 행은 2개의 행으로 2행 3열의 형태를 가집니다. 정리하면 인덱스는 칼럼에 포함되지 않는다. 그리고 참고로 최대한 인덱스보다는 칼럼(열)에 뜻(이름, 나이 등등)을 주는 게 좋습니다. 왜냐하면 그래야 수정과 접근에 용이하기 때문입니다. 행의 인덱스는 보통 User의 식별이나 대상의 개수를 나타내는데 이용됩니다.
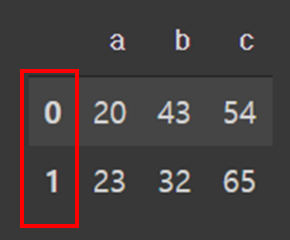
여기까지 이해하셨으면 다시 시리즈와 데이터 프레임으로 돌아옵시다. 시리즈와 데이터 프레임이란 모두 행열 형태의 자료구조입니다. 그런데 차이점은 시리즈는 칼럼이 1개이고데이터 프레임은 칼럼이 2개 이상인 자료구조입니다. 이 둘을 굳이 분리해서 이해할 필요 없고 만약 위와 같이 칼럼이 3개인 자료구조는 데이터 프레임이지만 위 DataFrame에서 칼럼 b, c를 지워버리면 위 DataFrame은 Series가 됩니다. 그래서 정리하면 아래와 같습니다.
| 자료구조 | 특징 | 형태(shape) |
| 데이터프레임(DataFrame) | 칼럼 1개, 인덱스 1열의 쌍으로 이루어짐 | (n,n) |
| 시리즈(Series) | 칼럼 n개(2개 이상), 인덱스 1열로 이루어짐 | (n,1) |
그럼 이제 바로 사용방법에 대해 알아봅시다.
2. Series와 DataFrame 생성 방법
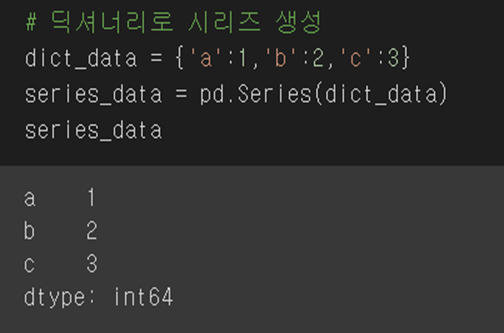
Series와 DataFrame을 생성하는 게 가장 핵심 포인트는 아래 데이터의 자리에 리스트, 튜플, 딕셔너리의 형태로 넣어주면 됩니다. 그래서 쓸 때도 저 같은 경우는 그냥 말 그대로 시리즈를 생성하려면 판다스의(pd.) 시리즈(Series)이런식으로 슥슥하고 데이터 프레임도 판다스의(pd.) 데이터 프레임(DataFrame) 이런 식으로 선언하면 됩니다.
그리고 참고로 넘파이도 똑같은 게 넘파이의 ndarray를 생성하려면 넘파이의(np.) 배열(ndarray) 이런식으로 하면 됩니다.
pd.DataFrame(데이터)
pd.Series(데이터)
그래서 아래 예시와 같이 생성할 수 있어요.


3. iloc와 loc를 활용한 데이터 조회 및 입력
3.1 loc와 iloc
iloc와 loc 모두 행열의 데이터를 조회하는 방법입니다. 기본 Python 같은 경우는 아래와 같은 배열이 있을 때 1행 1열의 배열을 인덱싱/슬라이싱하고 싶으면 변수[1,1]과 같이 조회하는데 데이터프레임은 아래와 같은 동일한 데이터가 있을 때 iloc 혹은 loc를 이용하여 인덱싱/슬라이싱해야한다.
[[2,3,4],
[5,6,7],
[8,9,10]]
결론은 iloc랑 loc는 판다스에서 데이터의 인덱싱/슬라이싱 방법이에요. 저도 처음 판다스를 배울 때는 이거 다 적어서 한 장에 정리하곤 했었는데 물론 그것도 좋지만 더 좋은건 역시 써보면서 익숙해지는 게 최고죠. 저 같은 경우는 이틀만 집중해서 써보니 손에 익더군요. (역시 익숙한 게 짱)
그럼 이제 iloc와 loc의 차이에 대해 알아봅시다. iloc나 loc나 위에서 말했듯 인덱싱 방법인데 이 둘의 차이는 iloc는 숫자로 인덱스의 위치를 받는 것이고 loc는 명칭으로 즉 문자로 위치를 받는 것입니다.
결국에 iloc나 loc나 아래와 같이 2가지의 인자를 받는데 첫 번째 인자는 행의 위치 두 번째 인자는 열의 위치를 받는다는 것만 기억하시면 됩니다.
데이터프레임명.iloc[조회할 행의 인덱스, 조회할 열의 인덱스]
데이터프레임명.loc[조회할 행의 명칭, 조회할 열의 명칭]
단 이때 주의할 점은 loc는 명칭 기반이지만 첫 번째 인자인 조회할 행의 명칭은 숫자가 오는 경우가 대부분입니다. 왜? 인덱스는 대부분 뜻을 주지 않고 숫자로 이루어져 있기 때문에 그렇게 됩니다.
즉 정리하면 인덱스가 문자로 되어있는 특수한 경우를 제외하고는 iloc랑 loc 둘 다 첫 번째 인자는 숫자로 행을 조회하고 다른 점은 iloc는 열의 위치를 숫자로 조회하고 loc는 문자(칼럼명)로 조회한다는 것입니다.
3.2 칼럼명으로 바로 조회 (iloc와 loc를 사용 X)
다음으로 iloc와 loc를 사용하지 않고 원하는 칼럼만 조회라는 방법을 살펴봅시다.
판다스만의 특징인데 아래와 같이 칼럼명을 대괄호 안에 넣어주면 그 칼럼만 조회할 수 있습니다.
데이터프레임명['조회할 칼럼명']
만약 조회하려는 칼럼이 여러 개라면 대괄호를 하나 더 쓰고 칼럼 리스트를 넣어주면 그 칼럼들만 조회할 수 있습니다.
데이터프레임명[['칼럼1','칼럼2','칼럼3']]
위를 이용하면 기존의 칼럼을 조합해서 새 칼럼을 만들 수도 있습니다.
df[‘new_col’]=df[‘col1’]+df[‘col2’]
3.3 불린 인덱싱
불린 인덱싱은 조건식과 함께 매우 유용하게 사용되는 데이터 조회 방법입니다.
불린 인덱싱은 조건식 중 True인 값만 반환합니다. 이 역시 다양하게 활용되는데 우선 iloc와 loc 없이 그냥 대괄호로 바로 접근해서 조건식을 쓸 수도 있습니다.
정리하면 아래와 같습니다.
| 구분 | 문법 | 특징 |
| 명칭 기반 조회 | 데이터프레임명.loc[조회할 행의 명칭, 조회할 열의 명칭(칼럼명)] | 문자로 |
| 인덱스 기반 조회 | 데이터프레임명.iloc[조회할 행의 인덱스, 조회할 열의 인덱스] | 숫자로 |
| 칼럼명으로 바로 조회 | 1개 - 데이터프레임명['조회할 칼럼명'] n개 - 데이터프레임명[['칼럼1','칼럼2','칼럼3']] | 바로 |
| 불린 인덱싱 | 조건식 중 True인 값만 반환 |
3.4 조건 값 조회 및 입력
조건 값 입력을 조건 값 조회와 동일한데 거기다 값만 넣어주면 됩니다. 즉 조건값을 조회한 식에 =K 이런 식으로 K라는 값을 할당하거나 1씩 더하거나 등의 연산 값을 입력할 수 있습니다.
예를 들어 df라는 이름의 아래와 같은 데이터 프레임이 있을 때 1행 1열의 값을 조회하고 싶다면

iloc로 해도 되지만 아래와 같은 코드로 1행 1열의 값을 조회하고 그 위치에 1을 더할 수 있습니다.
- df.loc[df[‘age’]==22,’sum’]+=1
4. 칼럼 추가/삭제
4.1 칼럼 추가
칼럼 추가는 아래와 같이 한 칼럼 값을 한 번에 할당하는 것과 마찬가지로 아래와 같습니다.
그런데 이때 이 칼럼이 없는 칼럼이면 그 칼럼을 추가하면서 값을 할당해주고 있는 칼럼이면 값만 바꿔줍니다.
- 변수['칼럼']=값
4.2 칼럼 삭제
칼럼을 삭제하는 데는 아래와 같이 두 가지 방법이 있는데 편한 방법을 사용하시면 될 것 같습니다.
- del 객체[칼럼]
- 객체.drop(‘칼럼’,axis=1)
5. 결측치 처리
결측치를 확인하는 대표적인 방법은. isnull(). sum() 메서드를 통해 결측치를 확인할 수 있고 칼럼 별로 위 함수를 붙이면 칼럼 별 결측치를 확인할 수 있습니다.
- df.fillna(n)
- df.fillna(method=‘ffill/pad’) //앞 방향
- df.fillna(method=‘bfill/backfill’) //뒷방향
- df.fillna(df.mean()[col])
6. 기본&유용한 함수 모음
| 명령어 | 뜻 |
| 객체=pd.read_csv(path) | 불러오기 |
| 변수.head() | 상위 n개 보기 |
| 변수.describe() | 데이터 분포도 확인 |
| 변수.info() | 칼럼 별 데이터 타입 확인 |
| 변수.shape | 객체의 크기 반환(행,열) |
| 변수.value_counts() | 데이터별 개수 확인 |
| 변수.index | 인덱스 리스트 반환 |
| 변수.columns | 칼럼 리스트 반환 |
| 변수.values | 칼럼 값 반환 |
| 변수.isnull() | 결측치 확인 |
| 변수.mean() | 평균값 출력 |
| 변수.max() | 최댓값 출력 |
| 변수.min() |
최솟값 출력
|
| 변수.sum() | 총 합계 출력 |
| 변수.replace(a,b) | a ➩ b로 바꿔줌 |
| 변수.astype(‘바꿀 자료형‘) | 자료형 바꿔줌 |
| 변수.to_numeric |
연산 가능한 형태로 변경
|
| 변수.to_numpy() |
넘파이로 변환
|
| 변수.to_dict() |
딕셔너리로 변환
|
| 변수.tolist() |
리스트로 변환
|
| 변수=df.corr() 변수[칼럼] |
유사도 구하기 - 해당 칼럼 기준으로 유사도 구함 |
7. 판다스 활용 팁 - 함수의 조합으로 원하는 결과 얻기
서두에 판다스가 파이썬의 유연함을 참 잘 살린 언어라고 말씀드렸는데 아래 예시를 보면서 확인해 봅시다.
df라는 예시 Series가 있습니다. 여기서 value_counts()를 적용해주면 이 카테고리 칼럼의 값 별 개수를 출력해줍니다.
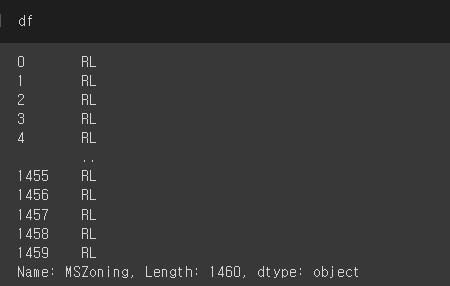
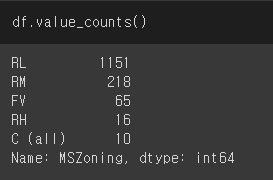
여기서 우리에게 value_counts()와 sum()이라는 함수가 있는데 values_counts()로 나온 결과의 합계를 보고 싶으면 어떻게 하면 될까요? value_counts() 뒤에 sum() 함수를 붙여주면 됩니다.
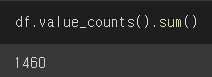
또 다른 예시로 어떤 칼럼에 mean() 함수가 적용해주면 칼럼 별 평균을 구해줍니다.
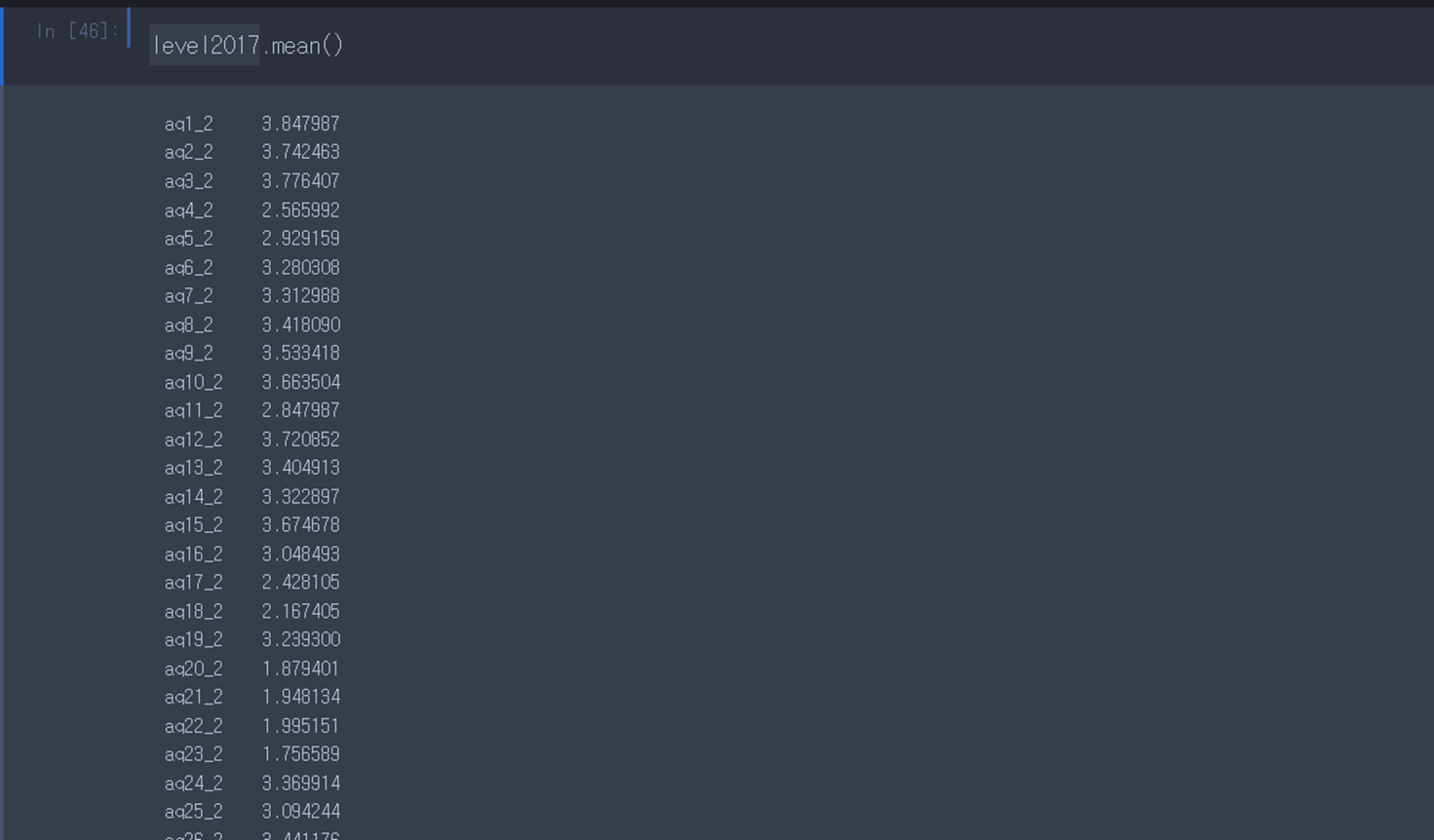
이때 이 칼럼별 평균의 평균을 구하고 싶다면 mean() 함수를 한 번 더 붙여주면 됩니다.
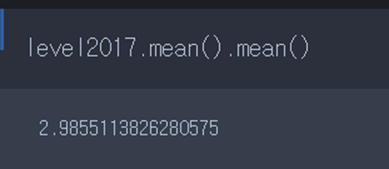
정리하면 아래와 같이 판다스 또는 넘파이는 함수들을 병렬적으로 배치하여 이전 명령의 출력 결과에 또 명령을 조합해서 사용할 수 있습니다.
변수.함수1( ).함수2( ).함수3( ) -
그리고 아래 함수의 조합은 종종 사용됩니다. 그러나 이 조합이 아니라도 여기서 중요한 건 함수들을 조합해 사용함으로써 원하는 작업을 할 수 있다는 것입니다.
- 변수.isnull().sum() - 칼럼별 결측치의 합계 출력
여기까지 긴 글 읽어주셔서 감사합니다.
오늘은 판다스의 기본 요약 정리 느낌으로 들고 왔는데 다음 시간에는
전체 데이터분석 Overview 관련 포스트를 올릴테니 참고해주세요.
이해되지 않거나 수정이 필요한 내용이 있다면 댓글 달아주세요.
'인공지능 > 데이터 분석' 카테고리의 다른 글
| Apache Spark와 Hadoop의 용도 및 차이점 (0) | 2022.06.04 |
|---|---|
| Word2Vec 라이브러리로 임베딩과 단어 유사도 구하기 (0) | 2022.05.25 |
| [데이터 분석] 넘파이(NumPy) 튜토리얼 겸 기초 총 정리 (feat. reshape에서 -1의 의미) (0) | 2022.05.01 |
| [Pandas] DataFrame 셀에 리스트(ndarray) 입력 / ValueError: Must have equal len keys and (0) | 2022.03.17 |
| [Pandas] 데이터프레임 셀 반복문 빠르게 돌리는 법 / Pandas를 Numpy로 변환 (0) | 2022.02.28 |



