
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 | 31 |
- 해킹
- html
- 리버싱
- 컴퓨터 구조
- 넘파이
- 인공지능
- webhacking
- 웹해킹
- 회귀 수식
- 알고리즘
- 보안
- 백준 알고리즘
- 리버싱 워게임
- 백준
- php
- 머신러닝
- sql injection
- 어셈블리어
- 리액트
- 웹
- 리버싱 문제
- writeup
- C언어
- abex crackme
- webhacking.kr
- MySQL
- CodeEngn
- 워게임
- 자바스크립트
- 리눅스
- Today
- Total
인공지능 개발일지
[Pandas] 데이터프레임 셀 반복문 빠르게 돌리는 법 / Pandas를 Numpy로 변환 본문
안녕하세요! Python의 반복문이 느리기로 유명하지만 가끔 반복문을 돌릴 때 시간이 말도 안 되게 오래 나올 때가 있습니다. 저 같은 경우는 2D 행렬에 대해서 셀마다 2중 반복문을 돌려서 값을 입력하는데 30시간이 나오길래
방법을 찾던 중 좋은 방법이 있어서 소개드립니다.
바로 2d 데이터프레임(판다스 자료구조) 행렬을 넘파이로 변환해서 반복문을 돌리는 것입니다.
이렇게 하니 속도가 무려 100배 정도 빨라져서 이래서 넘파이를 쓰는구나 느꼈습니다.
확실히 넘파이는 시각적으로 보긴 불편하지만 속도가 빠르고 데이터프레임은 보기 편하지만 속도는 느려서
이 둘을 적절하게 활용하면 좋을거 같습니다.
저는 이 아이디어를 얻고 다른데도 유용하게 사용이 되어서 도움이 되시길 바라며 올립니다.
이 전에 아이디어로 미니배치로 반복문을 쪼개서 각각 돌려보았지만 속도는 3배정도만 빨라져서
확실히 넘파이로 변환하는게 효율적임을 느꼈습니다.
(어쩐지 이상하더라고요. 그렇게 큰 데이터셋도 아닌데 넘나리 오래 걸리길래 빨리 돈 벌어서 컴퓨터 사자 싶었던 ㅜㅜ)
아래 사이즈가 9486 X 9486인 반복문을 돌리는 예시를 보면서 이에 예제를 소개드리겠습니다.
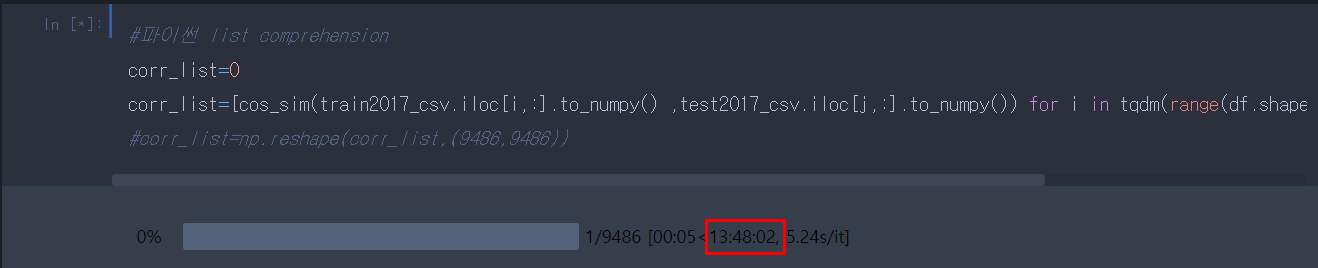
1. list comprehension으로 변환해서 반복문 돌리기 - 속도 2.5배 빨라짐
2. 미니배치로 반복할 사이즈 나누어서 여러 번의 반복문 돌리기 - 속도 3배 빨라짐
3. 데이터프레임을 넘파이로 변환하여 반복문 돌림 - 속도 약 100배 빨라짐
1. 파이썬 list comprehension으로 하면 빨라지나? (13h)
그렇지 않습니다. 제가 이것으로도 해보았는데 기존 이중 반복문에 비해 속도가 빨라지긴 했으나 여전히 오래 걸리는 모습을 확인할 수 있었습니다. 참고로 아래 코드에서 (.)으로 접근하는 게 시간이 오래 걸린대서 다른 걸로도 바꿔보았으니 결과가 그대로여서 그 과정은 생략하였습니다. ( 혹시 더 효율적인 코드가 생각나신다면 댓글 부탁드려요)
+전체 코드
1 | corr_list=[cos_sim(train2017_csv.iloc[i,:].to_numpy() ,test2017_csv.iloc[j,:].to_numpy()) for i in tqdm(range(df.shape[0])) for j in range(df.shape[0])] | cs |
2. 미니배치 - 배치 크기별 속도 차이
아래와 같이 크기를 나누어서 이중 반복문을 돌릴 때 유의하실 점은 안쪽 반복문의 크기는 고정시키고 바깥 루프의 크기를 나누어서 돌려야 합니다.
왜냐하면 안쪽 바깥문까지 나눌 경우 전체 데이터에 대해 나누어서 돌리기 까다롭기 때문이다.
예를 들어 위 반복문에서 다음 배치를 돌 때인 (500,1000)에 대하여 (750,250) 같은 경우에 대한 값은 안 구해지기 때문에 반드시 바깥 반복문에서만 크기를 나눠줘야 합니다.
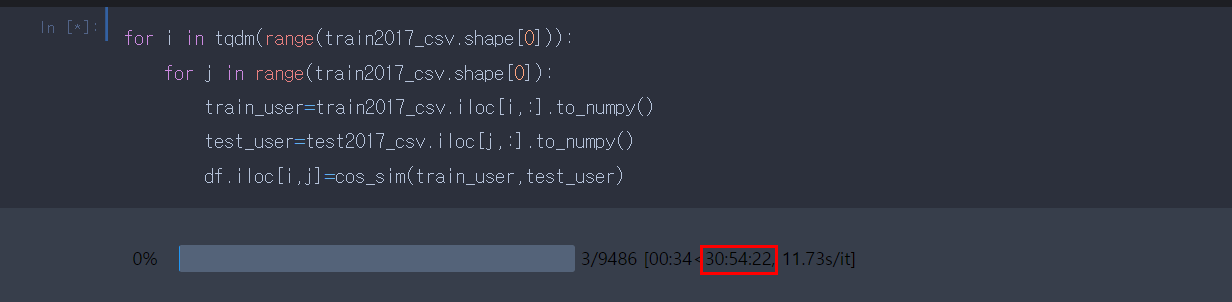
2.1 기존 반복문(default) - 31시간
저 같은 경우 9486 X 9486(train2017_csv.shape [0]==9486)의 데이터를 돌릴 것입니다.
기존 반복문처럼 쪼개지 않고 돌렸을 경우 약 31시간이라는 말도 안 되는 시간이 나옵니다.
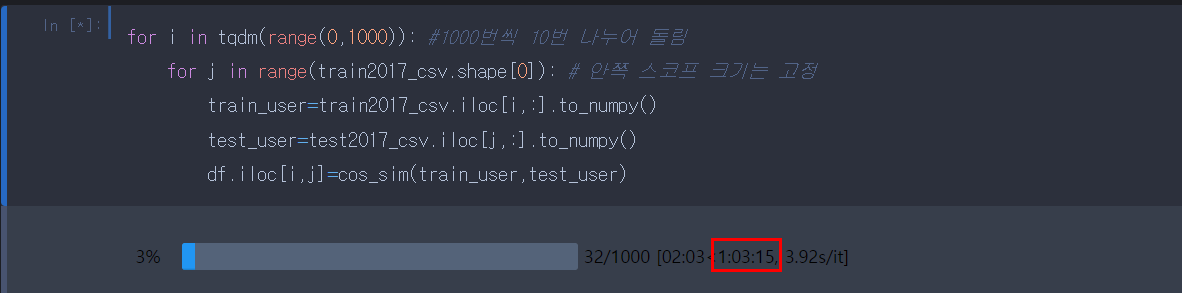
2.2 1000개(1시간) X 9.5번 = 9.5시간, 약 9.5시간
1000개씩 쪼개어서 약 10번을 할 경우 약 9.5시간으로 통째로 돌리는 것(30h)에 비해 1/3로 줄어든 것을 볼 수 있습니다.
하지만 그래도 여전히 긴 시간이기에 배치 사이즈를 더 쪼개 봅시다.
참고로 여기서 배치 사이즈를 1000으로 한다는 것의 의미는 [0~1000, 1001~2000, 2001~3000, ~~, 9000~9486] 이런 식으로 총 10번을 돌린다는 뜻입니다.
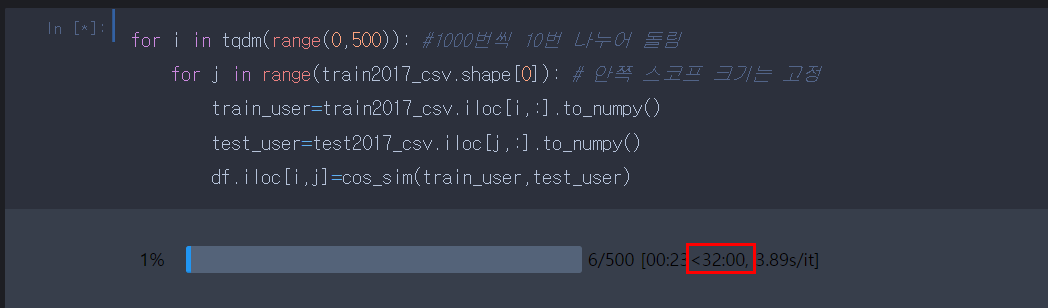
2.3 500개(30분) X 19번 = 9.5시간
하지만 여기서부터 임계점에 도달했는지 배치 사이즈가 500개일 때와 100개일 때 모두 총 학습시간은 9.5시간이 걸렸습니다. 그래서 저는 위의 방식인 1000*10으로 시간을 줄였습니다.
- 100개(7분) X 94번 = 약 10시간
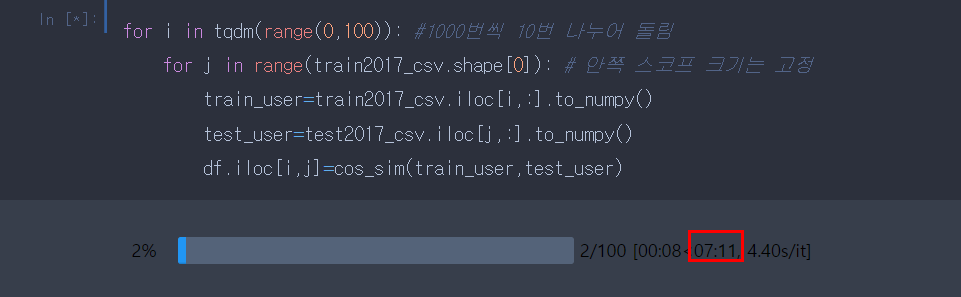
3. 판다스를 넘파이로 변환 !! 걸린 시간 - 26분
따흑 ㅜㅜ 보이시나요 넘파이 최고 .. 아래 코드는 위와 같은 9000X9000 사이즈의 데이터 프레임을. to_numpy()로 넘파이 배열로 바꿔서 반복문을 돌리는 예제입니다. 아래 예제를 통해 확실하게 같은 2d 자료구조도 판다스보다 넘파이로 변환해서 돌리는 게 더 빠름을 알 수 있습니다.


위 여러 예제를 통해 알 수 있는 것은 미니 배치를 반복문에 적용해도 일정한 속도가 빨라질 수 있다는 것입니다.
(그리고 이 게시글을 끝으로 저는 코랩 프로로 이사를 가버렸습니다.
코랩 짱짱맨..)
데이터프레임을 반복문에 돌리는데 속도가 너무 느리면 이 방법을 활용해 주시길 바랍니다.
그럼 읽어주셔서 감사합니다!
혹시 궁금한 게 있다면 댓글 달아주세요.
`
'인공지능 > 데이터 분석' 카테고리의 다른 글
| [데이터 분석] 넘파이(NumPy) 튜토리얼 겸 기초 총 정리 (feat. reshape에서 -1의 의미) (0) | 2022.05.01 |
|---|---|
| [Pandas] DataFrame 셀에 리스트(ndarray) 입력 / ValueError: Must have equal len keys and (0) | 2022.03.17 |
| [Python] Pandas DataFrame을 numpy 배열로 변환하는 방법 (0) | 2022.02.22 |
| [Pandas] DataFrame의 mean() 특정 열 누락, 전체 평균 값 안 나올 때 해결법 (0) | 2022.01.24 |
| [DACON] 잡케어 추천 알고리즘 데이터 분석 (0) | 2022.01.15 |

